안녕하세요!
컴퓨터구조 관련 글로 오랜만에 돌아왔습니다.
이전에 CPU 동작 원리에 대해 학습한 것 기억나시나요?
CPU 동작 원리: https://metastable.tistory.com/28
오늘은 응용버전인 파이프라이닝 (Pipelining)에 대해 배워보도록 하겠습니다.
Intro
먼저 파이프라이닝을 왜 해야 할까요?
그림으로 알아보겠습니다.
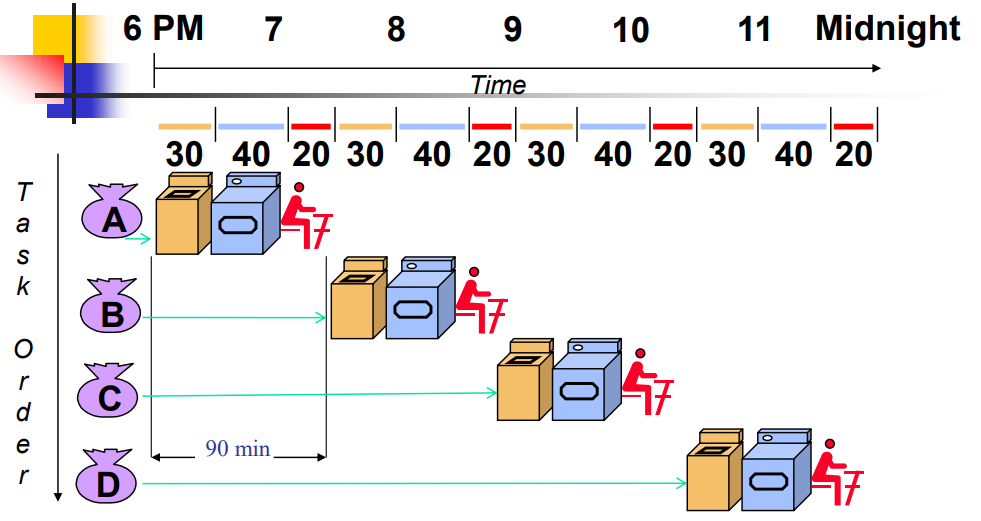
빨래방에서 빨래를 한다고 생각해볼까요?
우리는 세탁기를 30분 돌리고, 건조기를 40분 돌리고, 정리를 20분 해야 합니다.
이걸 한 사이클에 한다고 가정하면 위의 그림처럼 비효율적일 것입니다.
A가 세탁/건조/정리를 다 할때까지 B는 계속 기다려야 하죠..
그런데 A가 건조기를 사용할 동안 세탁기는 비어있죠?
그럼 B가 세탁기를 사용하면 안될까요?
여기서 착안한 것이 바로 파이프라이닝입니다.

A가 테이블을 사용할 동안
B가 건조기를 사용하고
C가 세탁기를 사용하면
기다리는 시간을 대폭 줄일 수 있습니다.
물론 각 사이클이 40분이 되었기 때문에 먼저 온 A 입장에서는 조금 손해일 수 있죠..
하지만 B 입장에서는 60분나 절약되었습니다.
이걸 CPU에 대입해볼까요?
첫 명령어나 짧은 명령어를 처리하는 시간은 조금 길어질 수 있으나,
다음 명령어들을 생각하면 전체적으로 효율이 증가하죠.
이걸 Throughput이 증가한다고 말합니다.
5-Stage Pipelining
기본적인 RISC 구조는 보통 5 단계로 나누어 파이프라이닝을 합니다.
- IF (Instruction Fetch)
메모리에서 명령어를 가져옵니다. - ID (Instruction Decode)
명령어를 해독하고 register를 읽습니다. - EX (Execute Operation)
Operation을 수행하고 Address를 계산합니다. - MEM (Memory Access)
메모리 Operand에 접근합니다. - WB (Write Back)
Register에 연산결과를 기록합니다.
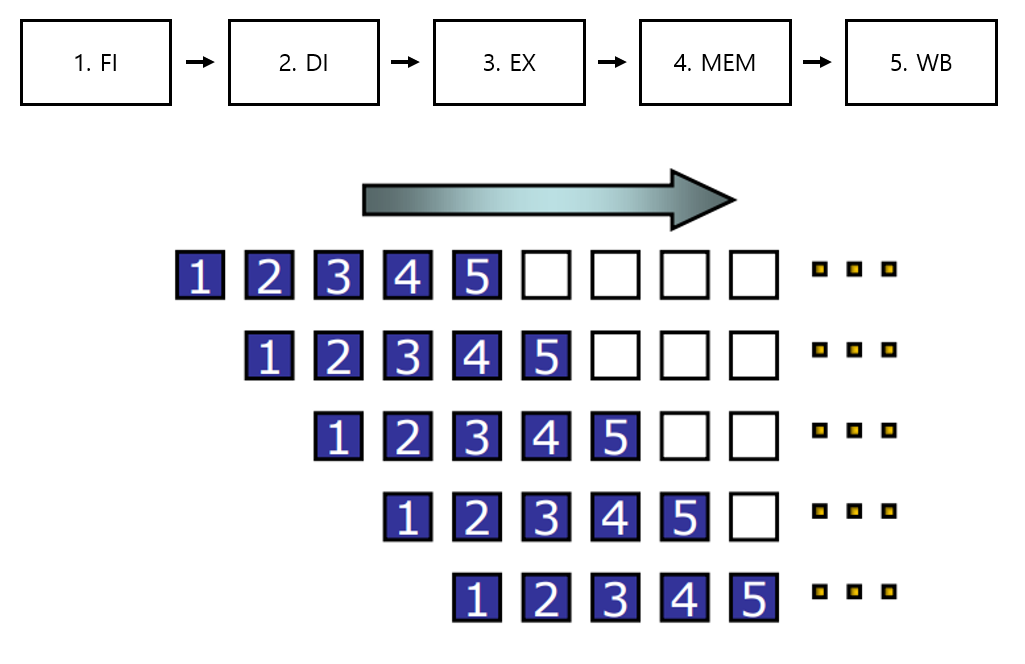
그림으로 나타내면 다음과 같습니다.
5단계로 나누어 Throughput을 늘릴 수 있습니다.
자 그러면 이제 CPU를 효율적으로 동작시킬 수 있나요?
효율은 굉장히 커졌지만 문제가 있습니다.
바로 Hazard 인데요
아래에서 설명 드리겠습니다.
Hazards
- Structural Hazard
구조적인 문제입니다.
여러 하드웨어가 동시에 같은 Instruction에 접근할 때 발생하는 Hazard입니다.
예를 들어 IF랑 MEM을 보겠습니다.
두 사이클 모두 메모리에 접근해야 합니다.
서로 다른 메모리에 접근한다면 문제가 없겠지만
같은 메모리라면 분명히 문제가 생기겠죠?
이때는 Stall을 사용해 사이클을 지연시켜 줍니다.
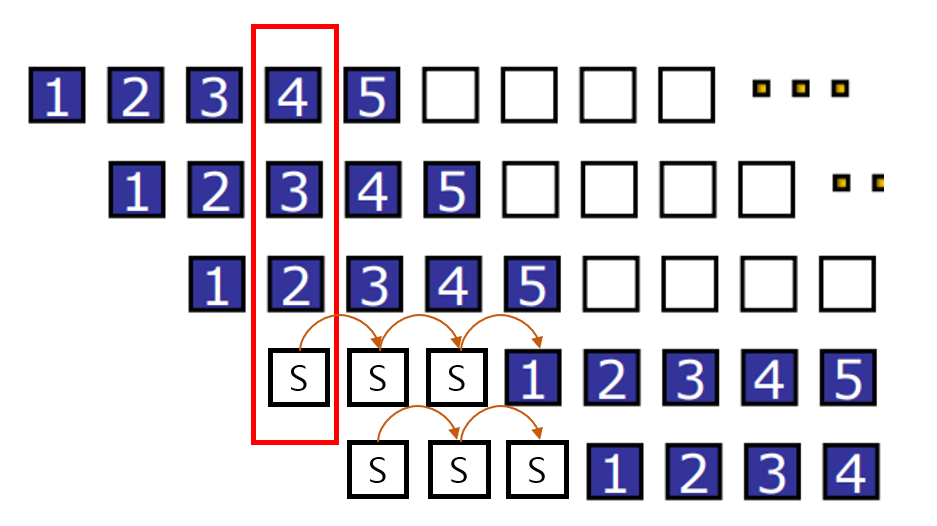
그림으로 나타내면 위와 같습니다.
1번 IF와 4번 MEM이 문제였기 때문에 둘을 같은 선상에 두면 안됩니다.
따라서 4번째줄부터는 Stall 시켜주어야 합니다.
- Data Hazard
데이터에 관한 Hazard 입니다.
명령어 순서가 다음과 같다고 가정해보겠습니다.

ADD 의 경우 아무 문제가 없습니다. 그냥 실행하면 되죠.
하지만 SUB 연산을 수행할 때 R1을 읽어와야 합니다.
파이프라이닝을 사용하면 ADD연산이 수행되기 전의 R1값을 일어올 것입니다.
사실 우리가 원하는 건 ADD연산 이후 업데이트 된 R1인데 말이죠..

그림으로 보면 ADD 연산의 WB이 완료된 이후 R1 값을 가져오는 것이 불가능해 보이죠?
여기에는 두 가지 해결책이 있습니다.
먼저 아까처럼 그냥 미루는 겁니다.

바로 이렇게 말이죠.
그런데 이러면 파이프라이닝의 의미가 있나요?
겨우 한 사이클만 당겨졌습니다.
이 문제를 해결하기 위해 Forwarding이라는 방식을 사용합니다.
그림부터 보시죠.
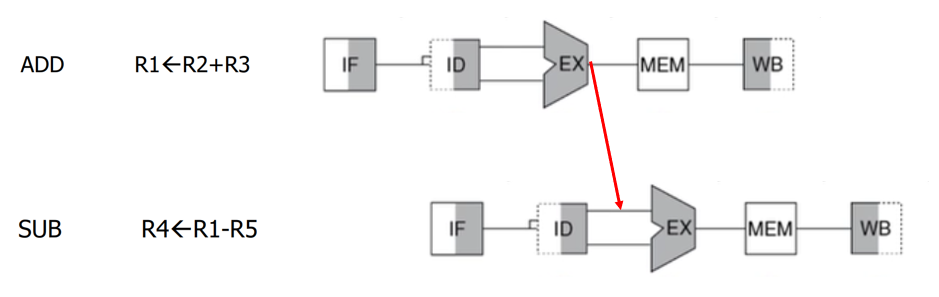
EX 후에서 EX 전으로 선을 하나 연결해주는 것입니다.
꼭 저장되고 꺼내서 사용하라는 법은 없잖아요?
EX에서 계산이 완료되면 그 값을 바로 가져다가 쓰는 방법입니다.
자, 그런데 이건 ADD의 경우고
Load 연산이면 어떨까요?
MEM 이후에 가능하니 Stall을 한 번 해줍니다.
Forwarding은 다른 말로 Bypassing이라고 부르기도 합니다.
- Control Hazard
Branch와 같은 명령어에 의해 PC 값이 변경될 때 일어나는 Hazard 입니다.
값이 변한다면 이전에 Fetch한 것들이 무의미하죠?
어차피 다시 Fetch해야 하니까요..
이것을 해결하기 위해 3가지 방법을 사용합니다.
1. Freeze Scheme
가장 간단한 방식입니다.
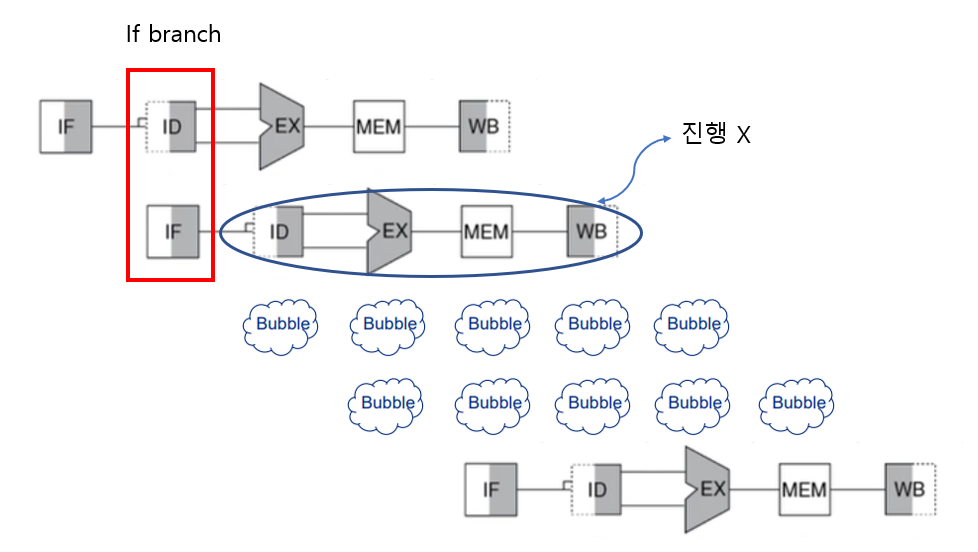
그냥 평소초럼 Pipelining을 하고 Branch가 일어나면 PC값을 알게될 때까지 멈추면 됩니다.
간단하긴 한데 조금 비효율적이죠?
2. Prediction
그냥 찍는겁니다.
틀리면 Stall이 발생하겠지만 맞으면 너무 좋죠!
예측에는 여러가지 방식이 존재합니다.
- 항상 branch가 일어날 것이다!
- 아니다. 항상 brach가 일어나지 않을 것이다.
- 이전의 결과를 참고해서 잘 찍어보자
등등.. 각각의 장단점이 존재합니다.
3. Delayed Branch
branch가 일어났을 때 버려지는 사이클이 존재하죠?
이때 branch와 상관없는 명령어를 가져와서 수행합니다.
그림을 보면 바로 이해가 되실겁니다.

branch 때문에 중간에 delay되는 구간이 존재하는데,
여기에 branch의 영향을 받지 않는 명령어를 가져오는 것입니다.
지금까지 CPU의 Pipelining과 그에 따른 Hazards를 살펴보았습니다.
'Digital Design > 컴퓨터구조' 카테고리의 다른 글
| [컴퓨터구조] ASIC Design Flow (2) | 2023.03.16 |
|---|---|
| [컴퓨터구조] 16bit CPU 설계 (Design with Verilog) (2) | 2023.01.12 |
| [컴퓨터구조] CPU 작동 원리 (0) | 2023.01.09 |
| [메모리] SRAM에 데이터 쓰고 읽기 (Design with Verilog) (0) | 2023.01.08 |
| [메모리] SRAM Full Custom Design (Layout) (0) | 2023.01.08 |




댓글