안녕하세요.
작년 중순 쯤 데이터 분석 능력을 키워보고자 데이콘 대회에 참여하였었는데요,
정말 도움이 많이 되어서 공유해보려고 합니다.
우선 저는 전자전기공학부라서 SW 지식이 약한 편에 속했습니다.
그래도 Python 기초는 공부한 경험이 있어서 대회를 기회 삼아 발전해 볼 생각으로 참여하였습니다.
코드를 약간 공유해보려고 하는데 오류가 있을 수 있다는 점 말씀드리려구요.
Python Code
제가 참여한 대회는 "쇼핑몰 지점별 매출액 분석시각화 경진대회" 입니다.
plt.figure(figsize = (10, 5))
sns.histplot(train.Date, bins = 139)
plt.title('Date Histogram', size = 20)
plt.show()
print('Date 종류의 개수는', len(train.Date.unique()), '개 입니다.')
print('Date의 최댓값은', train.Date.max(), '입니다.')
print('Date의 최솟값은', train.Date.min(), '입니다.')
print('Date 개수의 최댓값은', train.Date.value_counts().max(), '입니다.')
print('Date 개수의 최솟값은', train.Date.value_counts().min(), '입니다.')우선 데이터가 어떤 형태인지, 몇 개나 있는지 알아보았습니다.
%matplotlib inline
plt.style.use('ggplot')
feature = numeric_feature
temp_df = train[train['Date'] > '2011-11-11']
plt.figure(figsize = (20, 15))
plt.suptitle('Boxplots', fontsize = 40)
for i in range(len(feature)):
plt.subplot(3, 3, i+1)
plt.title(feature[i])
plt.boxplot(temp_df[feature[i]])
plt.show()또한 분포도를 확인하면서 데이터에 대한 감을 잡았습니다.
아무래도 Python 코딩 실력은 전공자에 비해 약하기 때문에 데이터의 모양새에 더 집중하였습니다.
plt.figure(figsize = (15, 10))
# 10번 매장의 상관관계 히트맵
heat_table = train[train['Store'] == 10].corr()
mask = np.zeros_like(heat_table)
mask[np.triu_indices_from(mask)] = True
heatmap_ax = sns.heatmap(heat_table, annot = True, mask = mask, cmap='coolwarm')
heatmap_ax.set_xticklabels(heatmap_ax.get_xticklabels(), fontsize=15, rotation=45)
heatmap_ax.set_yticklabels(heatmap_ax.get_yticklabels(), fontsize=15)
plt.title('correlation between features', fontsize=40)
plt.show()매장은 총 45개가 있었는데 이 정도는 확인할 수 있을 것 같아서 하나하나 다 보았습니다.
위의 코드는 10번째 매장의 데이터 상관관계를 보는 코드입니다.
# 2011년 11월 11일 이후의 데이터프레임
temp_df = train[train['Date'] > '2011-11-11']
target = 'Weekly_Sales'
feature = numeric_feature
plt.figure(figsize = (20, 15))
plt.suptitle('Scatter Plot after 2011.11.11', fontsize=40)
for i in range(len(feature[:-1])):
plt.subplot(3, 3, i+1)
plt.xlabel(feature[i])
plt.ylabel(target)
corr_score = temp_df[[feature[i], target]].corr().iloc[0, 1].round(2)
c = 'red' if corr_score > 0 else 'blue'
plt.scatter(temp_df[feature[i]], temp_df[target], color=c, label = f"corr = {corr_score}")
plt.legend(fontsize=15)
plt.tight_layout(rect = [0, 0.03, 1, 0.95])
plt.show()데이터를 받았을 때 앞부분은 비워진 값들이 꽤 있었습니다.
그래서 그 부분을 제외하고 뒷 부분부터 보니 상관관계가 조금씩 보이더라구요.

이런 식으로 다른 비전공자들도 읽고 이해하기 쉽도록 글도 써주었습니다.
하나하나 상세하게 설명하였더니 사람들이 잘 이해하였던 것 같아요.
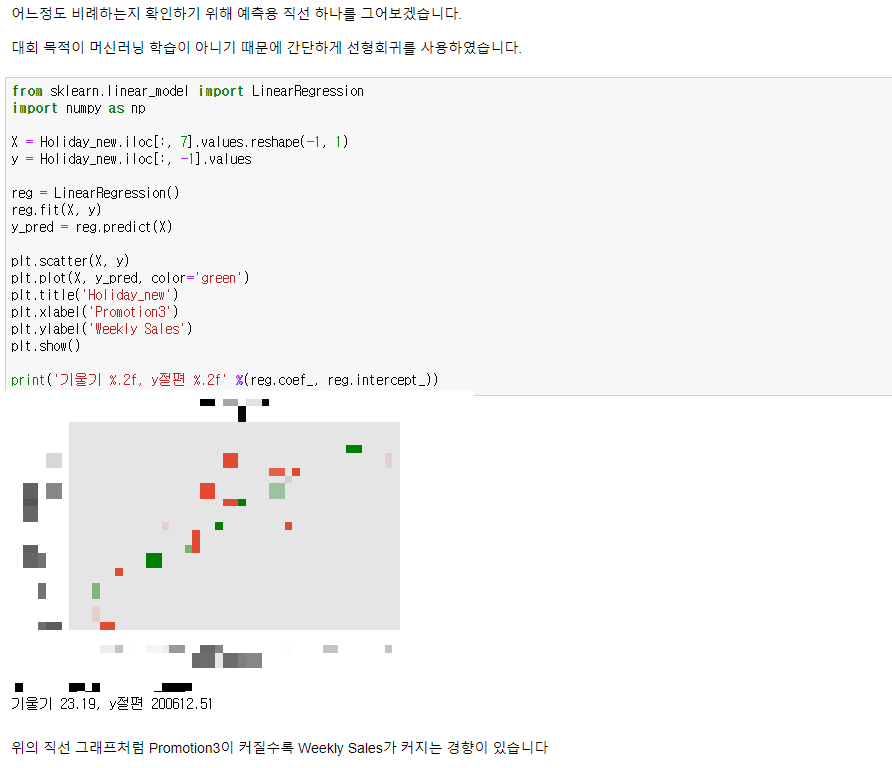
머신러닝에 대해서는 하나도 몰랐는데 공부를 하다보니 유용할 것 같아서
조금 섞어서 설명을 해봤습니다.

파이 그래프도 추가해주면서 설명의 친절도를 높여봤습니다.
이런 부분이 가점의 요인이 되지 않았을까 싶네요.
이렇게 여러 관점에서 설명을 하였더니 심사위원 분들이 좋게 봐주신 것 같아요.
결과적으로 여러 득표를 받아서 1위로 마무리 하였습니다.
공부도 하고 상장도 받아서 나름 좋은 기억으로 남았는데
여러분들도 관심이 있다면 주저하지 말고 도전해보셨으면 좋겠네요!
'Python' 카테고리의 다른 글
| [Python] 성적 분석 프로그램 (Python Code) (1) | 2023.01.13 |
|---|

댓글